Kafka本の商業版を出します
技術書典で頒布した「Kafkaをはじめる」を、インプレスR&D様から商業版として出すことになりました。
同人版では書ききれなかった以下の内容を追加して、全体的に書き直しています。
2022/09/16 (金) 発売です。
Kafkaを知らないけど気になる方や、学び直したい方は是非手に取っていただけますと幸いです。
よろしくお願いします!
DebeziumでPostgreSQLをCDCするときはロールにSELECT権限をつける
久しぶりにKafkaネタです。 Change Data Capture (CDC)でデータベースの変更をKafkaのイベントに変換するDebeziumを触り始めています。 PostgreSQLのレコードをKafkaに流すときに権限周りでハマったので、備忘録として残します。
Debeziumのおさらい
Debeziumはデータベースへのデータ登録、変更、削除をイベントに変換するソフトウェアです。 Kafka ConnectのSource Connectorとしてデプロイします。
Debeziumは今回扱うPostgreSQL以外にも、MySQL、Oracle、Db2といったRDBだけでなく、MongoDB、CassandraといったNoSQLもサポートしていることが特徴です。データベース固有の実装はConnector Pluginで抽象化されています。
PostgreSQL向けのConnector Pluginは、PostgreSQLの論理レプリケーションを通じてトランザクションログを読み込み、Kafkaのイベントに変換します。 そのため、PostgreSQL側にも論理レプリケーションを実行するための準備が必要です。
環境情報
| コンポーネント名 | バージョン |
|---|---|
| Kafka | 3.2 |
| PostgreSQL | 14.5 |
| Debezium | 1.9.5.Final |
課題
DebeziumのPostgreSQL Connectorは、PostgreSQLの論理レプリケーションを使用します。 PostgreSQLの論理レプリケーションはパブリケーション(PUBLICATION)と呼ばれる、レプリケーション対象のテーブルの集合および操作を定義したオブジェクトが必要になります。 Debeziumのデフォルトの設定では、Connectorがパブリケーションを自動生成します。 しかし本番環境ではConnectorのロールに渡す権限を最小限にするため、パブリケーションを事前に作成してConnectorから利用することが推奨されています。
ハマりポイントは事前にパブリケーションを作成する時にあります。
論理レプリケーションのプラグインに pgoutput を使用する場合、Debeziumのドキュメントに従って次のSQLでロールとパブリケーションを定義します。
ロールに REPLICATION 権限をつけることで論理レプリケーションを許可します。
また、作成するパブリケーション dbz_publication は、Debeziumがデフォルトで使用するパブリケーション名です。
-- Debeziumで使用するロール(=ユーザー) CREATE ROLE debezium WITH REPLICATION LOGIN PASSWORD '***'; -- 現在および今後作成される全てのテーブルをレプリケーション対象にする CREATE PUBLICATION dbz_publication FOR ALL TABLES;
しかし、この状態でDebeziumのConnectorを起動すると以下のログが出力され、permission denied for table contentsで起動に失敗します。
Snapshot step 1 - Preparing ...
Snapshot step 2 - Determining captured tables ...
Snapshot step 3 - Locking captured tables [テーブル名...]
Snapshot step 4 - Determining snapshot offset ...
Snapshot step 5 - Reading structure of captured tables
Snapshot step 6 - Persisting schema history
Snapshot step 7 - Snapshotting data ...
Snapshotting contents of N tables while still in transaction
Exporting data from table '<スキーマ名>.<テーブル名>' (1 of N tables)
For table '<スキーマ名>.<テーブル名>' using select statement: 'SELECT column1, column2, ... FROM <スキーマ名>.<テーブル名>'
Snapshot - Final stage
Producer failure [io.debezium.pipeline.ErrorHandler] io.debezium.DebeziumException: org.apache.kafka.connect.errors.ConnectException: Snapshotting of table <スキーマ名>.<テーブル名> failed
Caused by: org.postgresql.util.PSQLException: ERROR: permission denied for table <テーブル名>
(...後略...)
Connectorの状況をKafka ConnectのREST APIで確認しても FAILED ステータスになっています。
$ curl -s http://localhost:8083/connectors/postgresql-dbz-source-connector/status | jq .
{
"name": "postgresql-dbz-source-connector",
"connector": {...},
"tasks": [
{
"id": 0,
"state": "FAILED",
"worker_id": "10.20.33.45:8083",
"trace": "..."
}
],
"type": "source"
}
対策
Connectorの起動失敗メッセージはDebeziumがPostgreSQLに接続に使用するロールの権限エラーです。 DebeziumはConnector起動直後に、現在のテーブルの状態のスナップショットを取得します。 このスナップショットを取得する際にSELECT文を発行します。
select statement: 'SELECT column1, column2, ... FROM <スキーマ名>.<テーブル名>
上記のロールはスナップショットを取得するテーブルのSELECT権限を事前につける必要があります。
スキーマ内の全てのテーブルを対象とする場合、次のSQLで debezium ロールにSELECT権限をつけます。
GRANT SELECT ON ALL TABLES IN SCHEMA <スキーマ名> TO debezium;
再度Connectorを起動すると、無事イベントの連携が始まりました。
$ curl -s http://localhost:8083/connectors/postgresql-dbz-source-connector/status | jq .
{
"name": "postgresql-dbz-source-connector",
"connector": {...},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "10.20.33.45:8083",
"trace": "..."
}
],
"type": "source"
}
以上。
Open Libertyで出力するJSONログは末尾に改行を入れるな
Open LibertyでJSON形式のログを出す場面でハマったので、解決方法の備忘録です。
課題
以下の記事を参考にOpen Liberty上で稼働するJakarta EEアプリケーションのJSONログを標準出力に書き出そうとしました。 このアプリケーションは、Log4j 2でログをJSONに成形しています。
しかし、Open Libertyのserver.xmlで <logging appsWriteJson="true" /> を入れているのにも関わらず、
Open Liberty本体のJSONログの message フィールドに、アプリケーションのJSONログがラップされてしまう事象に遭遇しました。
以下のJSONはログの出力例です。JSONログの中に本来出力したかったJSONが含まれています。
{ "type": "liberty_message", "host": "...", "ibm_userDir”:”…”, ”ibm_serverName": "defaultServer", "message": "{\"timeMillis\":1659259664388,\"thread\":\"Default Executor-thread-8\",\"level\":\"INFO\",\"loggerName\":\"net.ponzmild.rest.resource.SampleResource\",\"message\":\"Called endpoint: GET /sample\",\"endOfBatch\":false,\"loggerFqcn\":\"org.apache.logging.slf4j.Log4jLogger\",\"threadId\":51,\"threadPriority\":5}\r", ... }
解決方法:JSONログ末尾に改行コードを入れない
答えはタイトル通りです。
Open Liberty本体から出力されたログの message フィールドの内容を見ると、ログメッセージ末尾に改行コード \r が含まれています。
Open LibertyではアプリケーションのJSONログ末尾に改行コードが含まれていると、JSON形式のログと解釈されないようです。
ドキュメントでこの挙動となる記述を見つけられませんでした。
改行コードを出力しないようにLog4j 2の設定ファイル log4j2.xml を設定します。
gistc985b983b747dbf8bdc303d0ace87528
JSONLayoutタグで eventEol="false" をセットすればOKです。
Logback等の別のログ出力ライブラリを使用している場合は、同等の設定をすれば解消できるはずです。
課題で挙げたログをOpen Libertyで再度出力させると、Open Libertyのログにラップされず標準出力に出力されるようになりました。
{"timeMillis":1659259784373,"thread":"Default Executor-thread-1","level":"INFO","loggerName":"...","message":"Called endpoint: GET /sample","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":37,"threadPriority":5}
環境情報
今回の課題と解決方法は次の環境で確認しています。 今後のOpen Libertyのバージョンアップで挙動は変わるかもしれません。
以上。
Javaアプリのトレース情報をJaegerにOpenTelemetry Protocolで送りつける
Jaeger v1.35からOpenTelemetry Protocol (OTEL) によるトレース情報を受け付けられるようになりました。 JavaアプリからOTELでトレース情報を送信・参照してみます。
元記事はこちら。
5月末にリリースされたJaeger v1.35からOpenTelemetryをネイティブサポートしたみたい。
— ぽんず (@ponzmild) 2022年6月9日
トレース情報をOTLPで直接Jaegerに投げつけられるから、Jaeger exporterをアプリにつけたり、OpenTelemetry Collectorを前段に置かなくてもトレースを見れる。これはいいぞ...!!https://t.co/E5xPDAuYdf
検証環境
| コンポーネント | バージョン |
|---|---|
| OS | macOS Monterey (12.4) |
| Java | OpenJDK Temurin-11.0.15+10 |
| Docker Desktop | 4.9.0 (80466) |
サンプルアプリ
Jakarta EE (Java EE) で実装された以下2本のアプリを題材とします。
| 名前 | トレース上の名称 | 説明 |
|---|---|---|
| フロントエンド・サービス | liberty-front-ui | ブラウザ上でリクエストを受け付け、バックエンド・サービスにAPIコールを送信する |
| バックエンド・サービス | liberty-backend-service | HTTPでリクエストを受け付け、組み込みDB (Derby DB)を操作する |
どちらもOpen Libertyアプリケーションサーバ上で稼働するものとします。 アプリ本体はOpen Libertyの以下のサンプルリポジトリを使用します。
Jaegerを立ち上げる
Midiumの記事に沿ってAll in OneのDockerコンテナを立てます。
docker run --name jaeger \ -e COLLECTOR_OTLP_ENABLED=true \ -p 16686:16686 \ -p 4317:4317 \ -p 4318:4318 \ jaegertracing/all-in-one:1.35
コンテナは数秒で起動します。ログを参照して公開した3つのポートのサーバが立ち上がっていればOKです。
docker logs jaeger
{"level":"info", ... ,"msg":"Starting GRPC server on endpoint 0.0.0.0:4317"}
{"level":"info", ... ,"msg":"Starting HTTP server on endpoint 0.0.0.0:4318"}
{"level":"info", ... ,"msg":"Starting HTTP server","port":16686,"addr":":16686"}
アプリケーションに設定を入れる
サンプルアプリはJava製なので、「OpenTelemetry Instrumentation for Java」を使用してトレース情報を取得・送信することにします。 Javaアプリ起動時にこのJava Agentを指定することで、様々なフレームワークやライブラリのトレース情報を自動取得してOTELで送信可能です。
まずはJava Agentを任意の場所にダウンロードします。 上記のGitHubリポジトリのReleaseページから最新のタグからダウンロードします。 本記事の執筆時点では、Version 1.14.0でした。
cd /path/to/opentelemetry wget https://github.com/open-telemetry/opentelemetry-java-instrumentation/releases/latest/download/opentelemetry-javaagent.jar
Java Agentでトレース情報を送信するためには、 JVM起動オプションに以下のパラメータをセットする必要があります。
| パラメータ名 | 設定値 | 説明 |
|---|---|---|
otel.exporter.otlp.endpoint |
http://localhost:4317 |
トレース情報送信先のOTELサーバ = Jaegerサーバのエンドポイント |
otel.traces.exporter |
otel |
トレース情報のexporter |
otel.metrics.exporter |
none |
メトリクス情報のexporter |
otel.resource.attributes |
service.name=<アプリ名> |
OpenTelemetryリソースの属性 |
otel.metrics.exporterをnoneで無効化してください。
本記事で使用するJaegerのバージョンではメトリクスをOTELで直接Jaegerに送信することはまだできません。
設定せずにアプリを起動すると以下のメッセージと共にエラーログが出力されます。
[err] [OkHttp http://localhost:4317/...] ERROR io.opentelemetry.exporter.internal.grpc.OkHttpGrpcExporter - Failed to export metrics. Server responded with UNIMPLEMENTED.
その他に設定できるパラメータは以下を参照してください。
opentelemetry-java/README.md at main · open-telemetry/opentelemetry-java · GitHub
さらにOpen Libertyサーバ固有の設定を1つ実施します。 JVM起動オプションを1箇所で管理するために以下の手順で jvm.options ファイルを作成して上記のパラメータを記載します。
フロントエンド・サービスの例
# サンプルアプリのリポジトリをダウンロード
git clone https://github.com/openliberty/guide-jpa-intro.git
cd guide-jpa-intro/finish/frontendUI
# jvm.optionsファイルを格納するディレクトリを事前に作成
mkdir -p src/main/liberty/config/configDropins/overrides
# jvm.optionsファイルを作成
cat <<EOF > src/main/liberty/config/configDropins/overrides/jvm.options
-javaagent:/path/to/opentelemetry/opentelemetry-javaagent.jar
-Dotel.exporter.otlp.endpoint=http://localhost:4317
-Dotel.traces.exporter=otlp
-Dotel.metrics.exporter=none
-Dotel.resource.attributes=service.name=liberty-frontend-ui
EOF
tree src/main/liberty
src/main/liberty
└── config
├── configDropins
│ └── overrides
│ └── jvm.options
└── server.xml
バックエンド・サービスの例
# サンプルアプリのリポジトリをダウンロード git clone https://github.com/openliberty/guide-jpa-intro.git cd guide-jpa-intro/finish/backendServices # jvm.optionsファイルを格納するディレクトリを事前に作成 mkdir -p src/main/liberty/config/configDropins/overrides # jvm.optionsファイルを作成 cat <<EOF > src/main/liberty/config/configDropins/overrides/jvm.options -javaagent:/path/to/opentelemetry/opentelemetry-javaagent.jar -Dotel.exporter.otlp.endpoint=http://localhost:4317 -Dotel.traces.exporter=otlp -Dotel.metrics.exporter=none -Dotel.resource.attributes=service.name=liberty-backend-service EOF
アプリケーションを起動してトレース情報を送信する
設定が完了したら早速アプリケーションを起動してトレース情報をJaegerに送信します。
# フロントエンド・サービス cd guide-jpa-intro/finish/frontendUI mvn liberty:run # バックエンド・サービス cd guide-jpa-intro/finish/backendServices mvn liberty:run
起動時のINFOログにOpenTelemetryのJava Agentのバージョンが表示されていれば準備完了です。
[main] INFO io.opentelemetry.javaagent.tooling.VersionLogger - opentelemetry-javaagent - version: 1.14.0
ブラウザで http://localhost:9090/eventmanager.jsf を開いて適当に参照、作成、更新、削除と操作します。
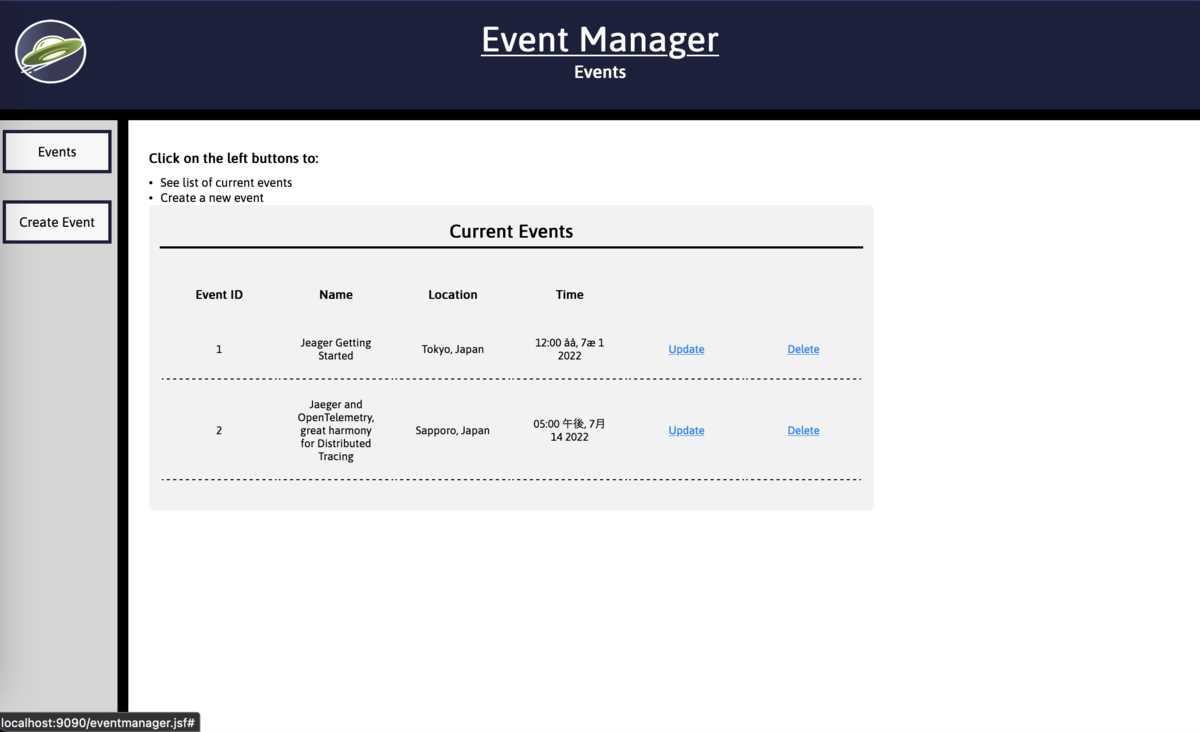
Jaegerでトレース情報を参照する
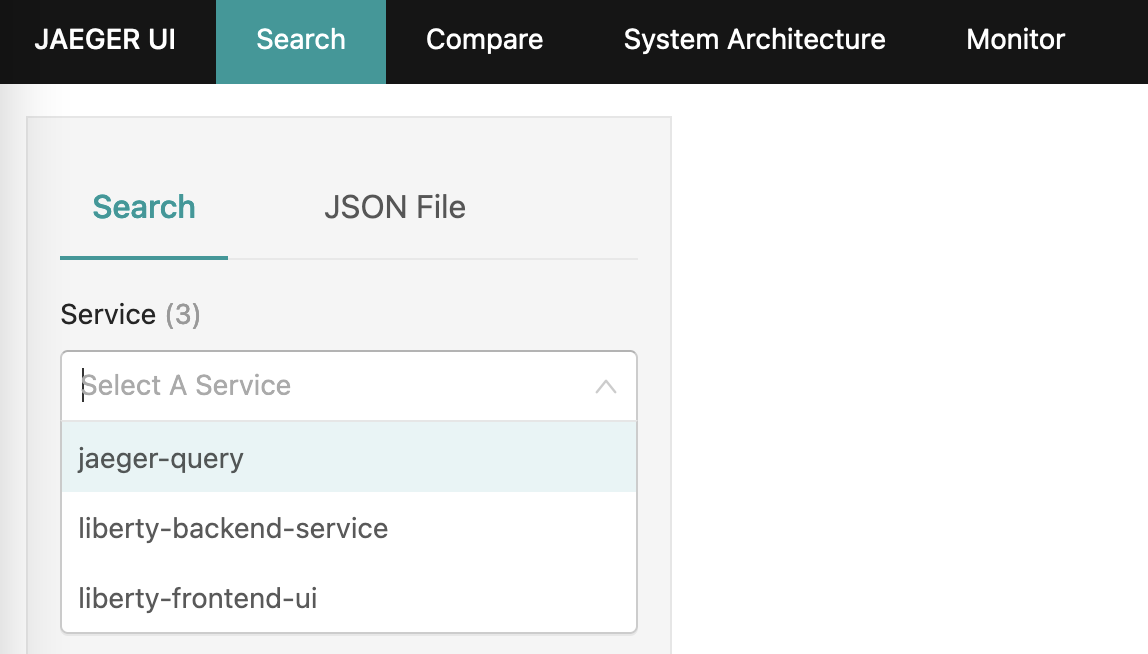
Jaeger UI (http://localhost:16686/) でトレース情報を参照すると、Serviceのプルダウンに先ほどJava Agentと一緒に起動したアプリ名が表示されています。
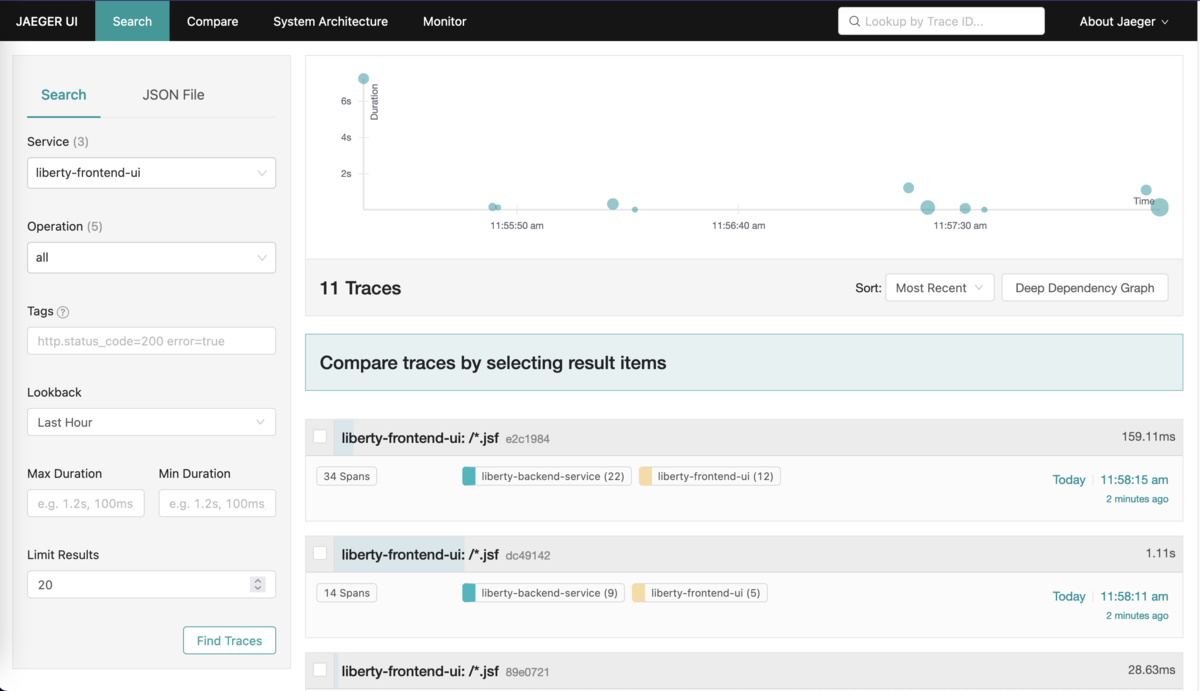
フロントエンド・サービスを選択して「Find Traces」ボタンを押すとトレース一覧、それぞれのトレースの実行時刻と処理時間が表示されます。トレース情報が取り込まれていますね。
トレース情報を1つ選択すると自動取得されたトレースのスパンの詳細を確認できます。 フロントエンド・サービスとバックエンド・サービスが1つに繋がって表示されています。
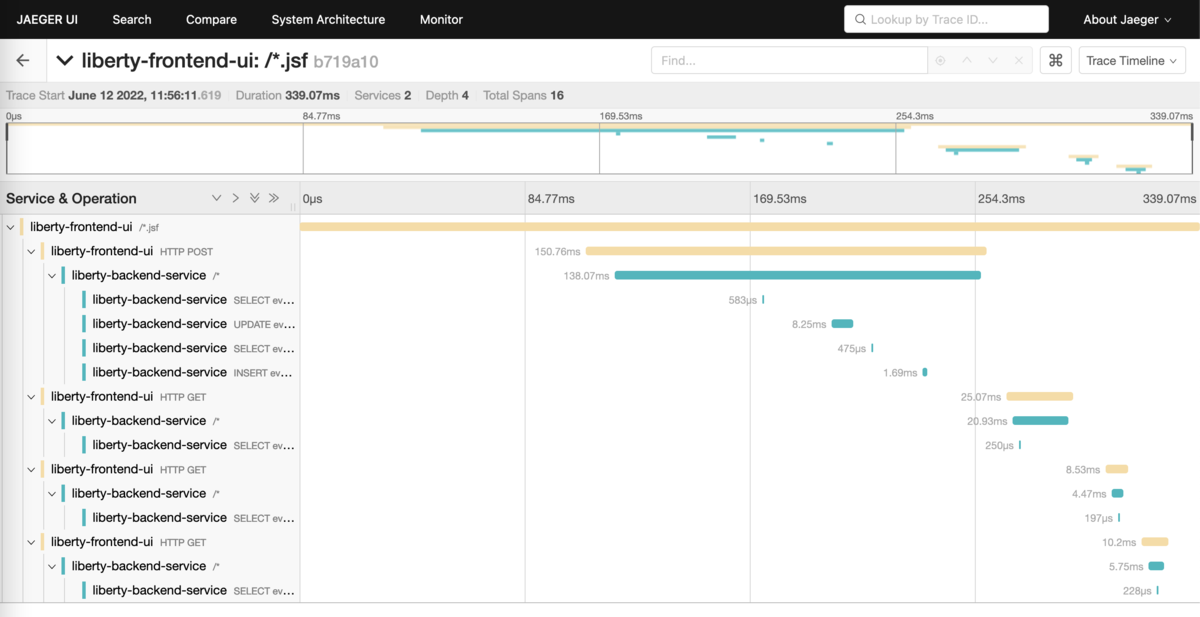
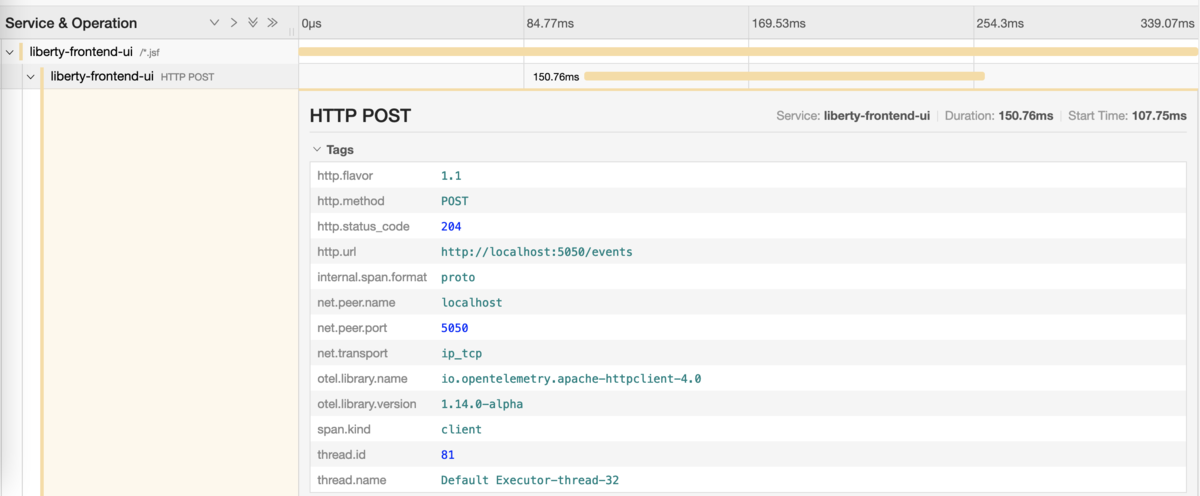
フロントエンド・サービスからバックエンド・サービスへのPOSTリクエストのスパンを開くと、Tagsに使用しているライブラリ名やリクエスト先のURLが見れました。Apache HTTP ClientでHTTPリクエストを投げているようですね。
今回のアップデートでトレース情報を取得・送信する敷居がグッと下がった気がしますね。どこかで使おう。
以上。
OpenShift CLIでKustomizeを使う
OpenShift CLIのリファレンスを眺めていたらKustomizeのマニフェストを使えそうだったので、メモ書きです。
環境情報
OpenShift CLI : 4.8.40
Kustomizeマニフェストを適用する
apply サブコマンドにKustomize用のフラグ --kustomize または -kをつけることで、直接Kustomizeのマニフェストを適用します。この方法ではKustomize形式のマニフェストから素のマニフェストをビルドと適用が同時に実行されます。
kubectlコマンドでも同じフラグを使えます。
以下のように oc apply の引数に上記フラグとエントリーポイントの kustomization.yaml が入ったディレクトリを指定します。
oc apply -k /path/to/kustomization/target
参考リンク:OpenShift CLI developer command reference - "oc apply"
Kustomizeマニフェストのビルドだけする
kustomize サブコマンドでKustomize形式のマニフェストから素のマニフェストをビルドして標準出力に吐き出します。
CLIドキュメントを見る限り、4.8系から使えるようになったサブコマンドのようです。(4.7系以前のドキュメントには記載がなかった)
この方法ではkustomizeのバイナリがなくても使えます。また、OpenShiftクラスタへの認証も不要でローカルに閉じて利用できます。あくまでKustomization形式のマニフェストのビルドだけ実行するので、別途 apply サブコマンド等で適用する必要があります。
生成結果を確認したり、さらにマニフェストを書き換える場合に使えそうです。
# ローカルのディレクトリ指定 oc kustomize /path/to/kustomization/target # リモートリポジトリのディレクトリ指定 oc kustomize 'https://github.com/argoproj/argo-cd.git/manifests/core-install?ref=v2.3.4'
参考リンク:OpenShift CLI developer command reference - "oc kustomize"
以上。
OpenShiftでJenkins ControllerとAgentを実行する
普段はエンタープライズのお客様と一緒に仕事しているのですが、 ビルドやデプロイのパイプラインには既存資産や知見を使いまわせるJenkinsを使いたいというニーズは未だに根強いと感じています。
しかしコンテナイメージの形でビルドツールやアプリケーションサーバなどが配布されているこの時代、 Jenkinsからもこれらのコンテナを使えると便利です。 少なくともかつてのようにController (Master) にいちいちインストールしたくない。
そこでこの記事ではOpenShift上にJenkinsをデプロイし、AgentもOpenShiftのPodで動かします。
検証環境
- OpenShift 4.10.3 (Developer Sandboxを利用しています)
- Jenkins 2.319.2
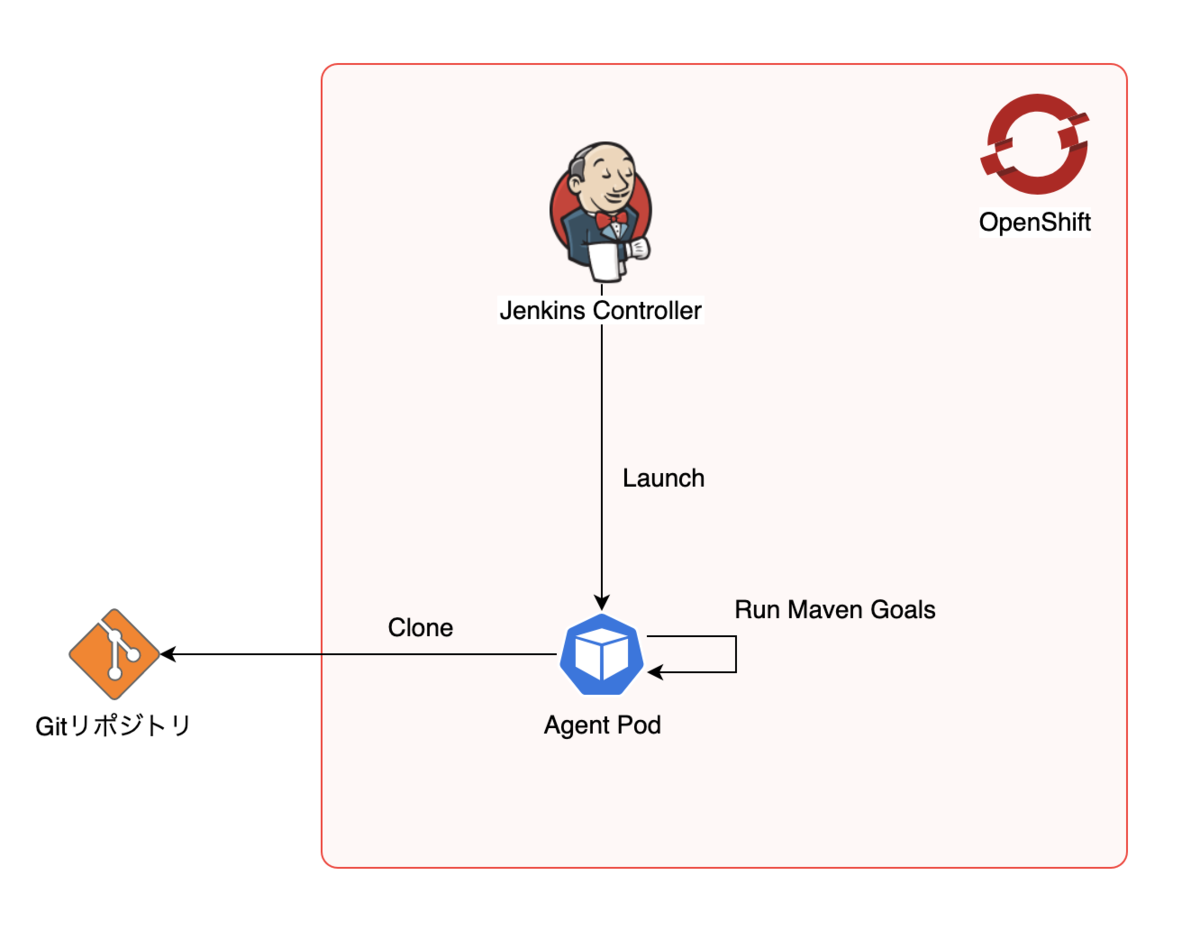
サンプル構成
今回組み立てる構成は以下の通りです。
- Jenkins ControllerとAgentはOpenShiftのPodで立てます。
- AgentのPodから外部のGitリポジトリ(GitHub)からソースコードをクローンします。
- Pod内のMavenコンテナでJavaのアプリケーションをビルドします。
- ビルド済みの成果物 (WARファイル) はJenkins Controllerにアーカイブします。
OpenShiftでJenkins Controllerを動かす
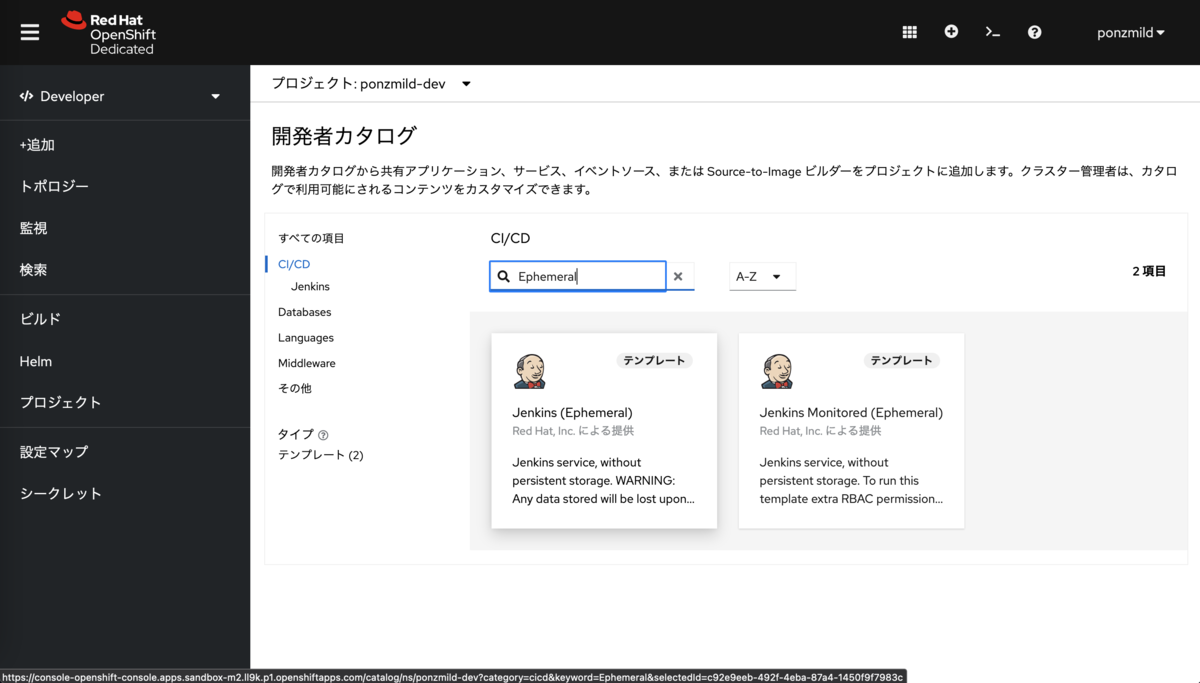
OpenShiftでは、Jenkins Controllerを簡単にプロビジョニングするためのテンプレートが用意されています。 テンプレートを開発者カタログから起動します。 今回は簡易のためにPVを使わないテンプレート ("Ephemeral" とあるもの) を選択します。
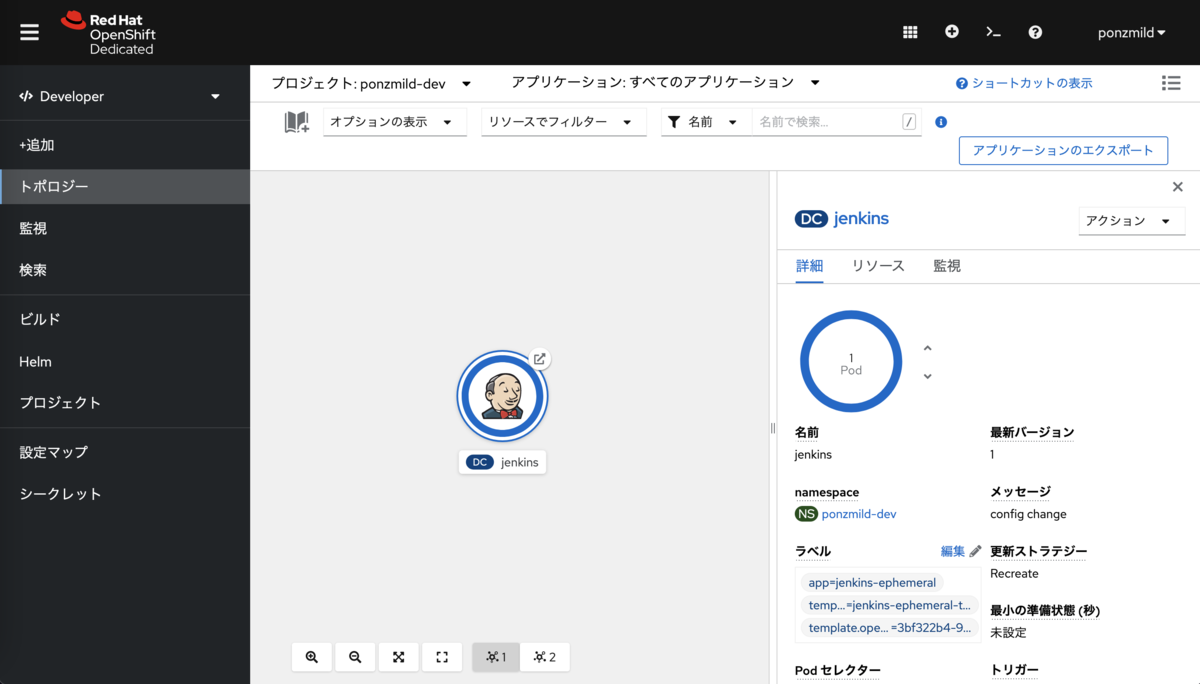
テンプレートから起動すると、5分程度でJenkins ControllerのPodが立ち上がります。 Topology画面か、Routeの設定からJenkinsのUIにアクセスできます。
初回アクセス時はOpenShiftの認証情報でSSOするための同意画面が表示されますが、"Login" "OK" と続けてボタンを押せばOKです。

Jenkins Controllerを起動する手順は以上です。
Jenkins Agentのパイプラインスクリプトを記述する
OpenShift (またはKubernetes) でJenkins AgentのPodを動かすためには、Kubernetes Pluginを使用します。 OpenShiftのテンプレートから起動したJenkins ControllerにはこのPluginは既にインストール・設定済みなので、 今回は特にPluginに関する作業は不要です。
Kubernetes Pluginの仕組みとしては、Pipelineの定義にYAMLを埋め込むかYAMLファイルを読み込ませることで一時的なPodを立ち上げます。 この一時的なPodをAgentとして利用します。Pipelineジョブ実行後はPodは自動的に削除されます。
早速Declarative Pipelineを記述していきます。
Declarative Pipeline that use OpenShift/Kubernete…
Agentの定義は、pipeline > agent > kubernetes に定義しています。
ビルドに使用するコンテナとして別途 maven コンテナを定義しています。
このコンテナ内でPipelineのstepを実行するため、defaultContainer 'maven' を指定しています。
また、Agent用に作成されるPodにはJenkins Controllerと疎通するための jnlp というコンテナが自動的に作成されます。
jnlp コンテナは特に指定せずともAgent定義に勝手に追加される仕組みになっていますが、設定を上書きする場合は記述が必要です。
上記のサンプルで最も重要な設定は、コンテナのホームディレクトリの指定です。
Kubernetes PluginにおいてはPodのホームディレクトリがデフォルト / となるため、OpenShiftではこのままではファイルの書き込みができません。回避策はKubernetes Pluginのドキュメント「Running on OpenShift」に記載されている以下の2つのいづれかを実施する必要があります。
- OpenShift用のJenkins Agentのベースイメージからビルドされたコンテナイメージを利用する。
- 別途 volume を作成して各コンテナの
/home/jenkinsにマウント & 環境変数HOMEにもこのパスで上書き指定する。
今回のサンプル構成では (2) を採用しています。
volumes セクションにemptyDirでhome-volumeを作成し、jnlp と maven の両方のコンテナにマウントしています。
パイプラインジョブを作成する
パイプラインスクリプトを記述したら、パイプラインジョブを作成します。 今回は「OpenShift Agent Sample」という名前を付けて作成します。
JenkinsのUIから 新規ジョブ作成 > パイプラインを選択します。
パイプラインジョブの設定後半に「パイプライン」のセクションがあるので、ここに先ほどのパイプラインスクリプトを貼り付けて保存します。
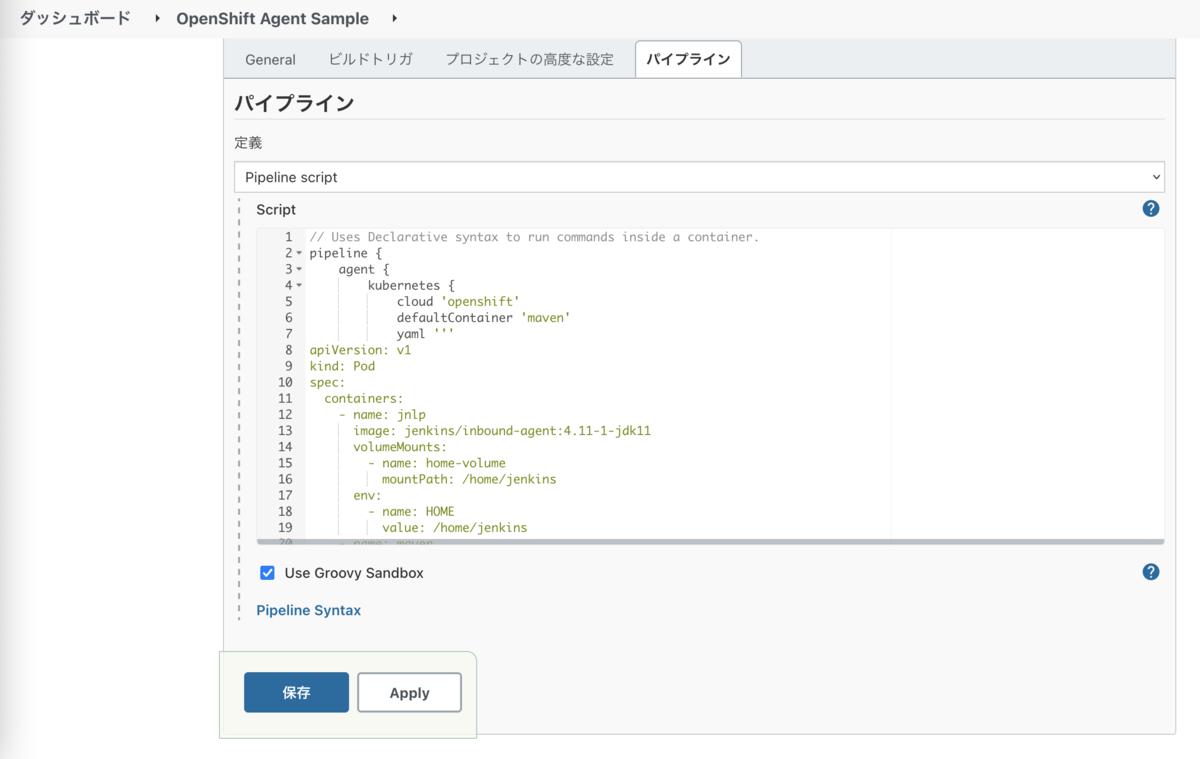
なお、今回はパイプラインスクリプトを直書きしましたが、プロダクション環境で動かすつもりであれば Jenkinsfile として別ファイルに外出ししてGitリポジトリから取得することが推奨です。(参考:「Top 10 Best Practices for Jenkins Pipeline Plugin」)
パイプラインジョブを動かしてみる
作成したパイプラインジョブを実行します。 パイプラインジョブを開き、「ビルドを実行」でジョブを開始します。
ジョブが開始されると、パイプライン名をプレフィックスとした名前のPodが立ち上がります。
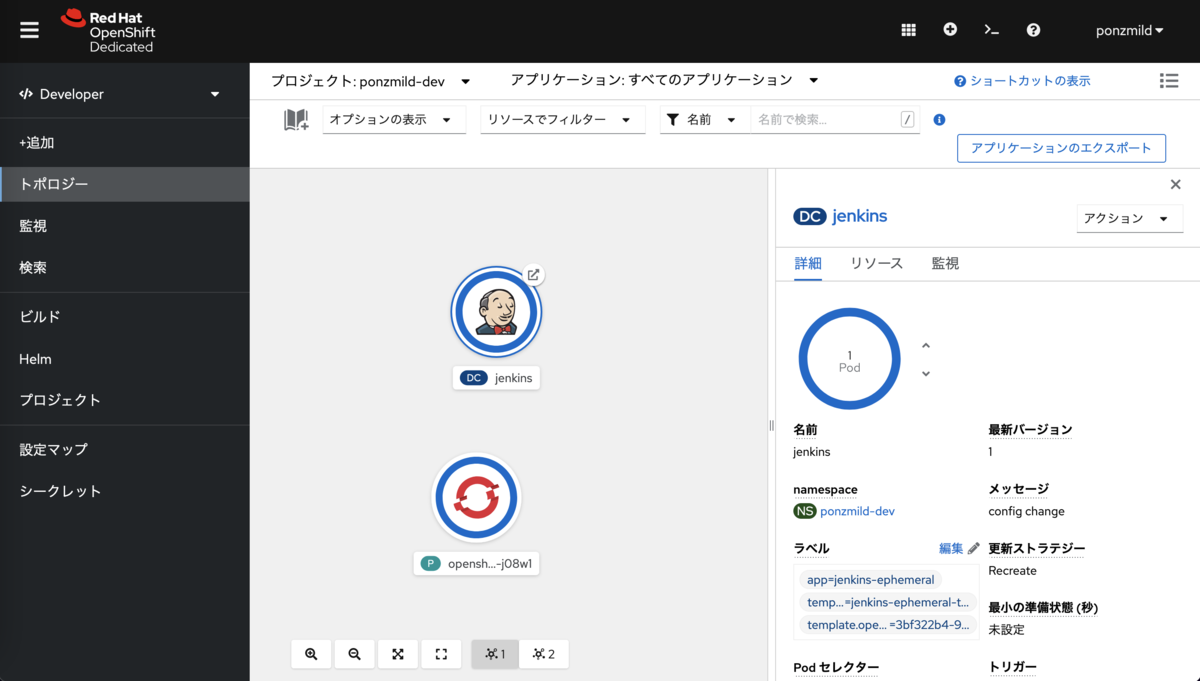
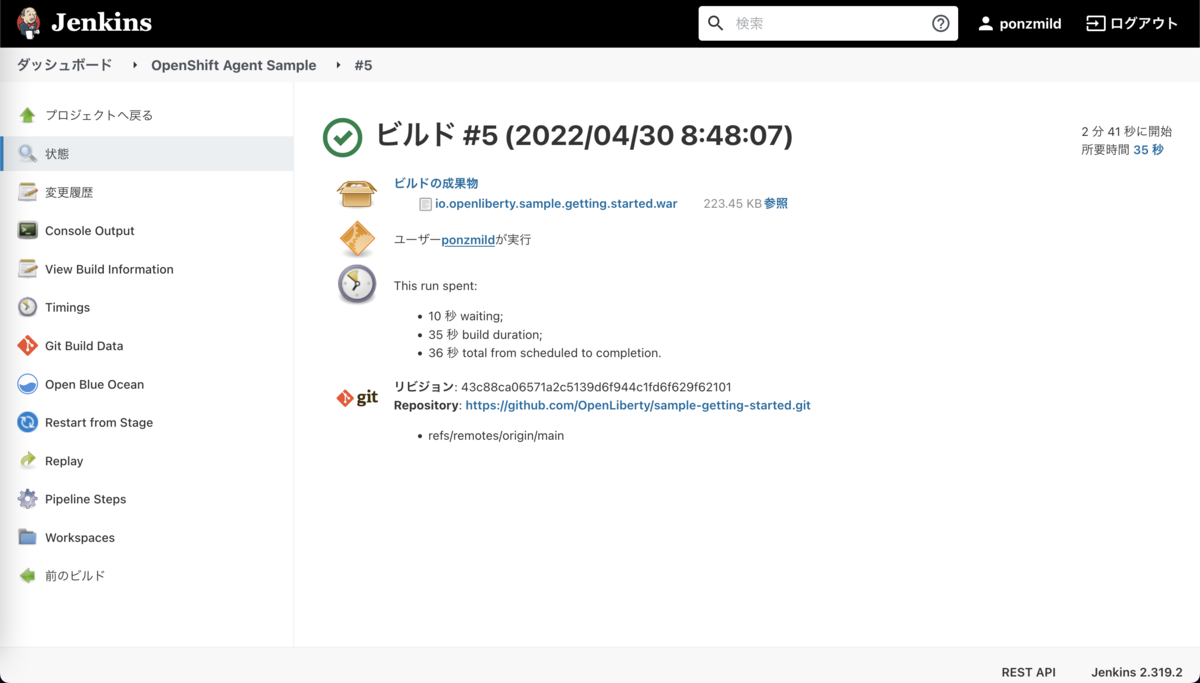
ビルドが無事完了すれば、「ビルド成果物」にWARファイルが登録されています。 また、実行ログは「コンソール出力」画面から参照できます。
うまくいかない例:ホームディレクトリを上書きしない場合
パイプラインスクリプトにおける最重要設定としてホームディレクトリの指定がありました。
もしホームディレクトリを上書きしない場合、ホームディレクトリが / となっているワーニングメッセージが表示されます。
また、ファイルの書き込みができないのでジョブが落ちます。
ホームディレクトリを上書きしない場合のログは以下の通りです。
[Pipeline] Start of Pipeline
(...中略...)
[WARNING] HOME is set to / in the jnlp container. You may encounter troubles when using tools or ssh client. This usually happens if the uid doesnt have any entry in /etc/passwd. Please add a user to your Dockerfile or set the HOME environment variable to a valid directory in the pod template definition.
Running on openshift-agent-sample-1-aaaaaa-bbbbb-ccccc in /home/jenkins/agent/workspace/OpenShift Agent Sample
[Pipeline] {
[Pipeline] writeFile
[Pipeline] writeFile
[Pipeline] container
[Pipeline] {
[Pipeline] sh
+ mvn clean package -B -ntp -DskipTests
[ERROR] Could not create local repository at /.m2/repository -> [Help 1]
(...中略...)
[Pipeline] // container
[Pipeline] }
[Pipeline] // node
[Pipeline] }
[Pipeline] // podTemplate
[Pipeline] End of Pipeline
ERROR: script returned exit code 1
Finished: FAILURE
以上。
skopeoのイメージコピー時にdigestを出力する
この記事は、skopeoでコンテナイメージをコピーしたときに同時にイメージdigestも一緒に出力できるからKubernetesのマニフェストへの埋め込みに便利だぞという話です。
skopeoはレジストリ間のコンテナイメージのコピーやタグ一覧の参照など、コンテナイメージのちょっとした操作を便利に実行できるユーティリティです。実践的な例としては、CIパイプラインでビルドしたイメージを検証環境や本番環境に昇格するといった使い方ができます。 この使い方をTektonから実行する解説記事がRed Hatさんのブログで紹介されています。
なぜdigestが必要か
Kubernetesなどのコンテナオーケストレーションツールでコンテナイメージを使うためには、イメージの識別子(タグなど)をマニフェストファイルに埋め込む必要があります。 識別子の埋め込むタイミングとしては、ビルド時やイメージの昇格時などが考えられるので、skopeoのイメージコピー操作と一緒に実行してあげると都合が良さそうです。
ここで問題になるのが、イメージの識別子として何を使うかです。 最も簡単なのはタグ名です。しかし、イメージを一意にかつ不変なものを指定するのであれば、digestの指定が確実です。 イメージの再プッシュが発生しうる場面では、同一のタグ名でも昨日と今日では別のイメージである可能性があります。 一方で同じタグ名でも内容が別のコンテナイメージであればdigestは別の値になります。
イメージの再プッシュが発生しない場面であればdigestではなくタグ名を識別子としても良いでしょう。 例えばAmazon ECRではレジストリのリポジトリ単位にイミュータブルタグを設定することでタグの再プッシュを防止できます。
digestを出力してみる
それではskopeoのコピー時にdigestを出力してみます。
開発用のレジストリ dev.registry.local/sample-app から 検証環境のレジストリ staging.registry.local/sample-app にイメージをコピーすると仮定します。
以下のサンプルでは digest.txt ファイルにdigestを出力しています。
ここでポイントは、 skopeoの copy コマンド実行時にdigestを出力するファイル名と一緒に --digestfile を指定します。
--digestfile オプションはskopeo 1.3.0から使えるようです。
$ skopeo copy --digestfile digest.txt \ docker://dev.registry.local/sample-app:20220313 \ docker://staging.registry.local/sample-app:20220313 Getting image source signatures Copying blob sha256:8d66994d054da0091fad11fb497b2a23c0cfd350d897d78d57f78b3200b90fd6 Copying blob sha256:52355207fda65c2219b38c373cef4a25e868a97641e484f1393e632843705bff Copying blob sha256:c934f4d5f4297067be69f40f99b06c810790e6ecf5d54e30bba34a2dfa4b7684 (...中略...) Writing manifest to image destination Storing signatures $ cat digest.txt sha256:aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
これでイメージを一意に特定するdigestを得られたので、マニフェストを sed などで置換すればコピーしたイメージを昇格先の環境にデプロイすることができそうです。
補足
ちなみにdigestをファイルに書き込むのはskopeo以外のツール/ユーティリティでも可能です。
例えばイメージビルドツールの kaniko だと --digest-file オプションをつけて実行することで同じことを実現できます。
以上。