タイトルの記事をQiitaに投稿しました。 やんごとなき理由でMaven Centralなどにアクセスできないオフライン環境で開発するシーン向けです。 Liberty Maven pluginのおかげでZIPファイルさえあればオンライン環境と同じ開発体験が得られるのはいいですね。
以上。
Red Hat OpenShiftで特定の時間帯だけPodをスケールアウト、それ以外の時間は少ない数 (できれば0) にスケールインという運用をKedaで実現してみます。AWSだとAmazon EC2 Auto Scalingに相当する機能の検証です。
Kedaはイベント駆動でKubernetesのPodをスケールするソフトウェアです。CNCFのGuraduatedプロジェクトであり、Apache 2.0ライセンスのOSSです。
Kedaには多種多様なイベントに対応したスケーラー(トリガー)があり、スケーラーの1つに時間を指定する cronスケーラー があります。時間帯指定によるスケールはこの cronスケーラー で実現します。その他のスケーラーは以下のリンクを参照してください。
KedaはKubernetesのディストリビューションに依らずインストール可能です。インストール方法はHelmチャートやOperatorで実施します。
OpenShiftであればKedaをアップストリームとした Custom Metrics Autoscaler Operator が提供されています。本記事ではこのOperatorでKedaをインストールして検証します。
執筆時点のバージョンのCustom Metrics Autoscaler Operatorでは cronスケーラー は公式のサポート対象には含まれていません。あくまでアップストリームのKedaに含まれているので使用可能という理解です。 実運用では最新のサポート状況をご確認いただき、動作検証を十分に行うことを推奨します。
カスタムメトリクスオートスケーラーは現在、Prometheus、CPU、メモリー、および Apache Kafka トリガーのみをサポートしています。
Custom Metrics Autoscaler OperatorをOpenShiftのWebコンソールからインストールします。 管理者ビューのOperatorHubから "Custom Metrics" や "Keda" で検索するとヒットします。

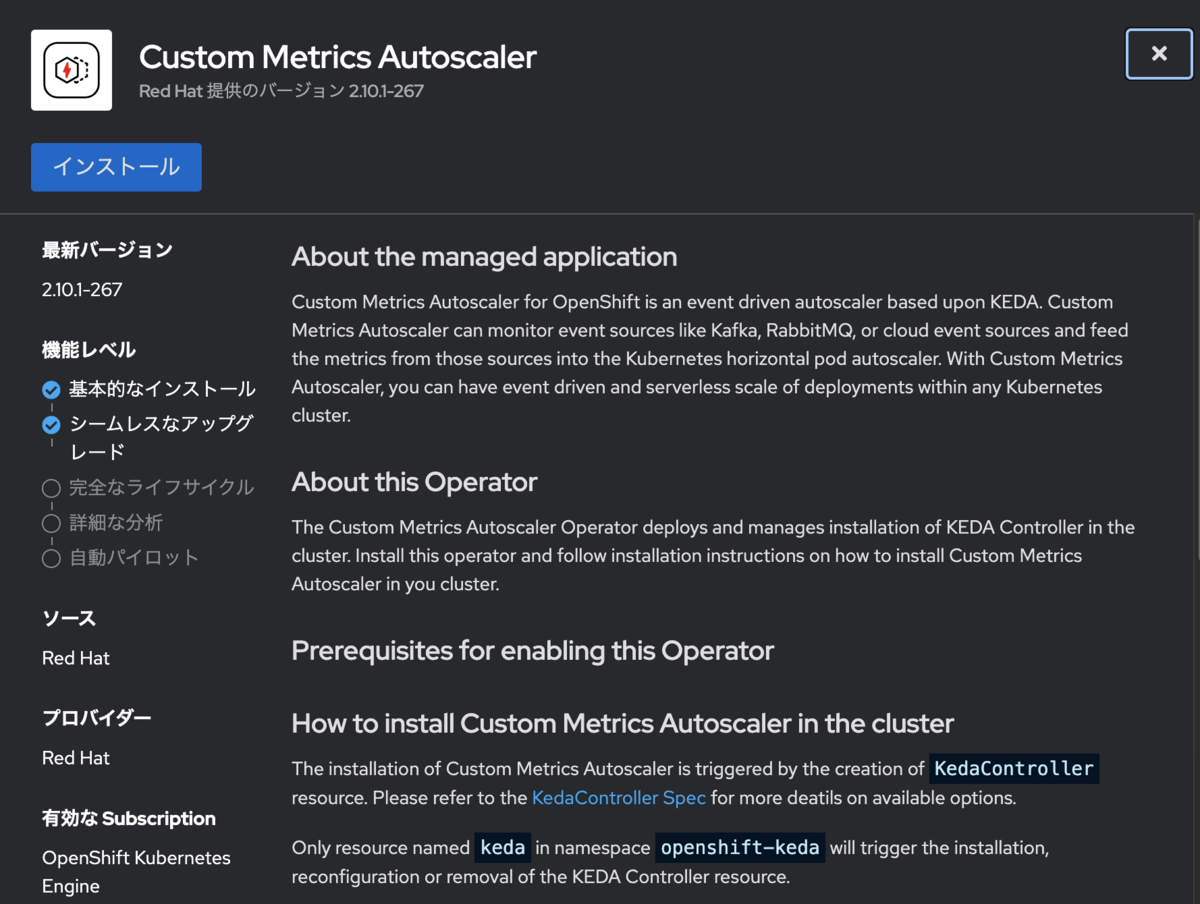
Operatorを選択して表示される設定画面に進み、設定値はデフォルト値のままでインストールすればOKです。自動的にOperatorを実行するプロジェクト openshift-keda が作成されます。
インストールガイドではインストールモードに「クラスターのすべてのnamespace (All namespaces on the cluster)」を指定するように記載がありましたが選択できません。「クラスターの特定のnamespace」で問題ありませんでした。
インストール済みOperatorで「Installed」と表示されたらOperatorのインストール作業は完了です。
APIグループ keda.sh のカスタムリソースが利用可能となっています。
$ oc api-resources --api-group keda.sh NAME SHORTNAMES APIVERSION NAMESPACED KIND clustertriggerauthentications cta,clustertriggerauth keda.sh/v1alpha1 false ClusterTriggerAuthentication kedacontrollers keda.sh/v1alpha1 true KedaController scaledjobs sj keda.sh/v1alpha1 true ScaledJob scaledobjects so keda.sh/v1alpha1 true ScaledObject triggerauthentications ta,triggerauth keda.sh/v1alpha1 true TriggerAuthentication
スケーラーの設定を投入する前に、Kedaの各種スケーラーを処理するコントローラーを作成します。コントローラーは KedaController リソースで作成します。
以下の keda-controller.yaml を作成して適用します。内容はOpenShift Webコンソールで作成するときのデフォルト値をそのまま使っています。
$ cat <<EOF | tee -a keda-controller.yaml
apiVersion: keda.sh/v1alpha1
kind: KedaController
metadata:
name: keda
namespace: openshift-keda
spec:
admissionWebhooks:
logEncoder: console
logLevel: info
metricsServer:
logLevel: '0'
operator:
logEncoder: console
logLevel: info
watchNamespace: ''
EOF
$ oc apply -f keda-controller.yaml
kedacontroller.keda.sh/keda created
$ oc get kedacontrollers -n openshift-keda
NAME AGE
keda 5s
スケールを試すサンプルアプリケーションを準備します。本記事ではNginxのサンプルを使用します。
oc new-app コマンドでNginxのビルダーイメージからコンテナイメージをビルドしてデプロイまで実施します。
$ oc new-app --name nginx nginx:1.20-ubi9~https://github.com/sclorg/nginx-ex
warning: Cannot check if git requires authentication.
--> Found image ea20902 (5 weeks old) in image stream "openshift/nginx" under tag "1.20-ubi9" for "nginx:1.20-ubi9"
Nginx 1.20
----------
Nginx is a web server and a reverse proxy server for HTTP, SMTP, POP3 and IMAP protocols, with a strong focus on high concurrency, performance and low memory usage. The container image provides a containerized packaging of the nginx 1.20 daemon. The image can be used as a base image for other applications based on nginx 1.20 web server. Nginx server image can be extended using source-to-image tool.
Tags: builder, nginx, nginx-120
* A source build using source code from https://github.com/sclorg/nginx-ex will be created
* The resulting image will be pushed to image stream tag "nginx:latest"
* Use 'oc start-build' to trigger a new build
--> Creating resources ...
imagestream.image.openshift.io "nginx" created
buildconfig.build.openshift.io "nginx" created
deployment.apps "nginx" created
service "nginx" created
--> Success
Build scheduled, use 'oc logs -f buildconfig/nginx' to track its progress.
Application is not exposed. You can expose services to the outside world by executing one or more of the commands below:
'oc expose service/nginx'
Run 'oc status' to view your app.
この時点ではレプリカ数は1です。
$ oc get po,deploy NAME READY STATUS RESTARTS AGE pod/nginx-1-build 0/1 Completed 0 3m26s pod/nginx-7ffdc8d89-tmz6z 1/1 Running 0 49s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 1/1 1 1 3m26s
本記事の本題です。Kedaではスケーラーを用いたPodのスケール設定を ScaledObject または ScaledJob リソースで定義します。
常時起動してリクエストを受け付けるアプリケーションであれば ScaledObject 、特定のメトリクスに反応して単発起動するアプリケーションであれば ScaledJob と使い分けます。
本記事ではWebサーバーであるNginxを使っているので ScaledObject リソースでスケーラーを設定します。
ScaledObject リソースを設定例を次に示します。
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: nginx namespace: ponzmild-dev spec: scaleTargetRef: kind: Deployment name: nginx minReplicaCount: 0 maxReplicaCount: 3 triggers: - type: cron metadata: timezone: Asia/Tokyo start: 00 21 * * * end: 30 21 * * * desiredReplicas: "3"
この ScaledObject では以下の内容を定義しています。
cron式の時間をタイムゾーンで指定可能なのは嬉しいですね。UTCに変換するために9時間引く手間が省けます。
スケーラーの設定を keda-scaled-object-nginx.yaml に保存してOpenShiftに適用します。
$ oc apply -f keda-scaled-object-nginx.yaml scaledobject.keda.sh/nginx created
ScaledObject リソースを作成直後 (20:45)ScaledObject リソースを作成した時点からスケールする様子を確認します。
リソース作成時点ではcron式で時間帯以外と判定されているのでレプリカ数が1から0にスケールインしています。
$ oc get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx 0/0 0 0 8m47s $ oc get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-nginx Deployment/nginx <unknown>/1 (avg) 1 3 0 16s $ oc get so NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE nginx apps/v1.Deployment nginx 0 3 cron True False Unknown 53s
イベントログを参照するとスケールインしたことが記録されています。
$ oc get events --namespace ponzmild-dev | tail -10 2m Normal KEDAScalersStarted scaledobject/nginx Started scalers watch 2m Normal ScaledObjectReady scaledobject/nginx ScaledObject is ready for scaling 2m Normal KEDAScaleTargetDeactivated scaledobject/nginx Deactivated apps/v1.Deployment ponzmild-dev/nginx from 1 to 0 2m Normal ScalingReplicaSet deployment/nginx Scaled down replica set nginx-7ffdc8d89 to 0 from 1
cron式で指定した21:00を迎えるとスケーラーの定義通りPodレプリカ数が3にスケールアウトしています。ScaledObjectに紐づくHPAが3に設定していますね。
$ oc get po,deploy,hpa,so NAME READY STATUS RESTARTS AGE pod/nginx-1-build 0/1 Completed 0 32m pod/nginx-7ffdc8d89-5jwvc 1/1 Running 0 19m pod/nginx-7ffdc8d89-mjtmw 1/1 Running 0 19m pod/nginx-7ffdc8d89-tq8wb 1/1 Running 0 19m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 3/3 3 3 32m NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE horizontalpodautoscaler.autoscaling/keda-hpa-nginx Deployment/nginx 1/1 (avg) 1 3 3 23m NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE scaledobject.keda.sh/nginx apps/v1.Deployment nginx 0 3 cron True True False 23m
また、Kedaの仕組みとして最初にレプリカ数を0→1に変更、続いてレプリカ数を1→3と順番にスケールアウトしていることがイベントログからわかります。
5m Normal KEDAScaleTargetActivated scaledobject/nginx Scaled apps/v1.Deployment ponzmild-dev/nginx from 0 to 1 5m Normal ScalingReplicaSet deployment/nginx Scaled up replica set nginx-7ffdc8d89 to 3 from 1
cron式の指定時間を終えるとレプリカ数は0にスケールインします。
$ oc get po,deploy,hpa,so NAME READY STATUS RESTARTS AGE pod/nginx-1-build 0/1 Completed 0 47m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 0/0 0 0 47m NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE horizontalpodautoscaler.autoscaling/keda-hpa-nginx Deployment/nginx <unknown>/1 (avg) 1 3 0 39m NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE scaledobject.keda.sh/nginx apps/v1.Deployment nginx 0 3 cron True False False 39m
イベントにも一気に0にスケールしたことが記録されています。
$ oc get events --namespace ponzmild-dev | tail -10 73s Normal KEDAScaleTargetDeactivated scaledobject/nginx Deactivated apps/v1.Deployment ponzmild-dev/nginx from 3 to 0 73s Normal ScalingReplicaSet deployment/nginx Scaled down replica set nginx-7ffdc8d89 to 0 from 3
ちなみにスケールインが実行されたのはend時間に指定した 21:30 ではなく 21:35 でした。これはScaledObjectの cooldownperiod でスケールインの猶予時間がデフォルト5分で指定されているからです。実運用ではこの猶予時間を適切に設定する必要がありそうです。
Scaling Deployments, StatefulSets & Custom Resources | KEDA
The period to wait after the last trigger reported active before scaling the resource back to 0. By default, it’s 5 minutes (300 seconds).
以上。
AnsibleからTerraformを呼び出すAnsible Collection cloud.terraform があることを知りました。
Ansibleのワークフローの中でクラウドリソースの作成だけTerraformに任せたい場合に便利そうなので試してみます。
cloud.terraform.terraform ... terraform [plan | apply | destroy] 相当cloud.terraform.terraform_output ... terraform output 相当以下の環境、バージョンで検証します。
Ansible PlaybookからTerraformの実行と実行ログの出力、TerraformではAWSにVPCとSubnetを作成してみます。
また、最終系のディレクトリ構成は次の通りです。
Terraformのファイル群は terraform ディレクトリ、ログファイルの出力先は out ディレクトリとします。
.
├── ansible.cfg
├── inventories
│ └── demo.yml
├── out
│ ├── YYYYmmddTHHMMSS_terraform_apply.log
│ └── YYYYmmddTHHMMSS_terraform_apply.log
├── playbook.yml
├── requirements.txt
├── requirements.yml
└── terraform
├── main.tf
├── outputs.tf
└── variables.tf
ansible-galaxy コマンドでTerraform collectionをインストールします。
ansible-galaxy collection install cloud.terraform
terraform ディレクトリの下にAWSリソースを作成するtfファイルを作成します。
main.tfにAWSリソースの作成処理、入力変数定義を variables.tf 、そして出力変数定義を outputs.tf を記述します。
main.tf
# main.tf terraform { required_providers { aws = { source = "hashicorp/aws" version = "5.12.0" } } } provider "aws" { region = var.region default_tags { tags = { ManagedBy : "Terraform" } } } resource "aws_vpc" "demo" { cidr_block = "10.23.0.0/16" } resource "aws_subnet" "demo1" { cidr_block = "10.23.45.0/24" vpc_id = aws_vpc.demo.id }
variables.tf
# variables.tf variable "region" { type = string description = "AWS Region" default = "ap-northeast-1" }
outputs.tf
# outputs.tf output "vpc_id" { value = aws_vpc.demo.id description = "VPC ID" }
Terraformを呼び出すAnsible Playbookを記述します。記述例は次のとおりです。
--- - name: Terraform Demo hosts: localhost tasks: - name: Provisioning infrastructure cloud.terraform.terraform: project_path: "{{ playbook_dir }}/terraform" state: present force_init: true register: ret_tf - name: Write provisioning log ansible.builtin.copy: content: "{{ ret_tf.stdout }}" dest: "{{ playbook_dir }}/out/{{ ansible_date_time.iso8601_basic_short }}_terraform_apply.log" mode: "0644"
cloud.terraform.terraform モジュールで特定のディレクトリ配下のtfファイルを適用します。ディレクトリは project_path で指定しますが、絶対パスで指定しましょう。相対パスだとエラーとなりました。
state パラメータは present だと terraform apply 、absent を指定すると terraform destroy と同じ挙動をします。 terraform plan だけトリッキーで present を指定しつつ ansible-playbook コマンドをチェックモードで実行します。
1点注意すべき点として、Terraform実行途中のログは標準出力に表示されません。Terraformの実行ログはモジュールの stdout 変数に格納されるので ansible.builtin.copy モジュールなどでファイルに出力しておきます。Terraformの処理が中断されたらどこまで適用されたか分からないのは不便ですね。今後の改善に期待です。
ansible-playbook コマンドで Terraform collection を含むPlaybookを実行します。
ansible-playbook -i inventories/demo.yml playbook.yml
Terraformを実行するタスクは処理成功時に changed と表示するはずです。
PLAY [Terraform Demo] **************************************************************************************************** TASK [Gathering Facts] *************************************************************************************************** ok: [localhost] TASK [Provisioning infrastructure] *************************************************************************************** changed: [localhost] TASK [Write provisioning log] ******************************************************************************************** changed: [localhost] PLAY RECAP *************************************************************************************************************** localhost : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Terraformの実行ログ output/YYYYmmddTHHMMSS_terraform_apply.log を参照すると、Terraform CLIと同じような実行ログが出力されていますね。
aws_vpc.demo: Creating... aws_vpc.demo: Creation complete after 1s [id=vpc-000000000000] aws_subnet.demo1: Creating... aws_subnet.demo1: Creation complete after 0s [id=subnet-123412341234] Apply complete! Resources: 2 added, 0 changed, 0 destroyed. Outputs: vpc_id = "vpc-000000000000"
試しに同じPlaybookを再実行するとTerraformモジュールのタスクが ok に変わります。Terraformの冪等性がAnsible Collectionにも反映されていますね。
PLAY [Terraform Demo] **************************************************************************************************** TASK [Gathering Facts] *************************************************************************************************** ok: [localhost] TASK [Provisioning infrastructure] *************************************************************************************** ok: [localhost] TASK [Write provisioning log] ******************************************************************************************** changed: [localhost] PLAY RECAP *************************************************************************************************************** localhost : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Terraform collectionは次のユースケースで使えそうです。
以上。
エンタープライズ向けシステムの世界にいるとユーザー管理・認証にLDAPサーバーを使っている場面に直面します。 LDAPサーバーはOSSのOpenLDAPだったり、389 Directory Server (Red Hat)、Tivoli Directory Server (IBM)、あるいはMicrosoft Active Directoryかもしれません。
ユーザー認証というコンテキストであれば、2023年現在だとアプリケーションを新規開発するなら認証プロトコルにOIDCかSAMLを使うでしょう。素のLDAPプロトコルで認証するロジックを書くのは面倒です。OIDC/SAMLであればシングル・サインオン可能です。ただし、ユーザー管理のリポジトリとしてLDAPサーバーを (積極的/消極的どちらかの理由で) 有効活用したいケースがあります。
この記事では認証ソフトウェアのKeycloakを用いて、LDAPサーバーをバックエンドに据えて、LDAPユーザーでOIDC認証を実現する方法を残します。
この記事ではLDAPサーバーにOpenLDAPを使用します。 OpenLDAPとKeycloakはどちらもDockerコンテナとして起動します。 以下のコンテナイメージを使用します。
| コンポーネント名 | コンテナイメージ |
|---|---|
| OpenLDAP | docker.io/bitnami/openldap:2.6.5 |
| Keycloak | quay.io/keycloak/keycloak:22.0.1 |
LDAPは次の設定でユーザー情報が投入されているとします。
dc=example,dc=comusershatenademo1, パスワード: H0ge_Fugahatenademo2, パスワード: P1yo-piY0コンテナをDocker Composeでまとめて起動します。
まずはDocker Compose定義ファイル compose.yml を作成します。 compose.yml のサンプルを以下に示します。
内容としてはOpenLDAPに管理者ユーザー admin と、環境情報で定義したLDAP設定、2つのユーザー情報 hatenademo1 hatenademo2 を環境変数で投入しています。
Keycloakは開発モード start-dev で動かします。
version: "3" services: openldap: container_name: openldap image: docker.io/bitnami/openldap:2.6.5 ports: - "1389:1389" environment: LDAP_ADMIN_USERNAME: admin LDAP_ADMIN_PASSWORD: adminpassword LDAP_USERS: hatenademo1,hatenademo2 LDAP_PASSWORDS: H0ge_Fuga,P1yo-piY0 LDAP_ROOT: dc=example,dc=com LDAP_USER_DC: users # ou=users LDAP_ALLOW_ANON_BINDING: no keycloak: container_name: keycloak image: quay.io/keycloak/keycloak:22.0.1 command: ["start-dev"] ports: - "8080:8080" environment: KEYCLOAK_ADMIN: keycloakadmin KEYCLOAK_ADMIN_PASSWORD: Kc_Admin_Pass KC_HEALTH_ENABLED: true healthcheck: test: ["CMD", "curl", "--head", "-fsS", "http://localhost:8080/health/ready"] interval: 10s timeout: 3s retries: 3 start_period: 30s
compose.yml をインプットに、docker compose コマンドでコンテナを起動します。
$ docker compose up -d [+] Running 3/3 ✔ Network hatenademo_default Created ✔ Container openldap Started ✔ Container keycloak Started
OpenLDAPサーバーに ldapsearch コマンドを発行すると、2つのユーザーが登録されています。
$ ldapsearch -x -H "ldap://localhost:1389" -D "cn=admin,dc=example,dc=com" -W -b "ou=users,dc=example,dc=com" "objectClass=inetOrgPerson" Enter LDAP Password: (adminユーザーのパスワード) (...中略...) # hatenademo1, users, example.com dn: cn=hatenademo1,ou=users,dc=example,dc=com cn: User1 cn: hatenademo1 sn: Bar1 objectClass: inetOrgPerson uid: hatenademo1 (...その他の属性は省略...) # hatenademo2, users, example.com dn: cn=hatenademo2,ou=users,dc=example,dc=com cn: User2 cn: hatenademo2 sn: Bar2 objectClass: inetOrgPerson uid: hatenademo2 (...その他の属性は省略...)
ここから本題です。KeycloakがLDAPサーバーをバックエンドのユーザーリポジトリとして扱う設定は、Keycloakの「ユーザーフェデレーション」という機能で扱います。フェデレーション設定をKeycloakのレルム ldap-demo に入れると仮定して後続に設定を進めます。
コンテナで立てたKeycloakの管理コンソールに http://localhost:8080 でアクセスし、Keycloak管理者ユーザーでログインします。
レルムが未作成の場合はログイン後にレルム ldap-demo を作成してください。
レルム選択後に左メニュー最下部に「User federation」メニューがあるので選択します。 フェデレーション設定するプロバイダーの選択画面が表示されるので「Add Ldap provider」を選択して設定入力画面に遷移します。
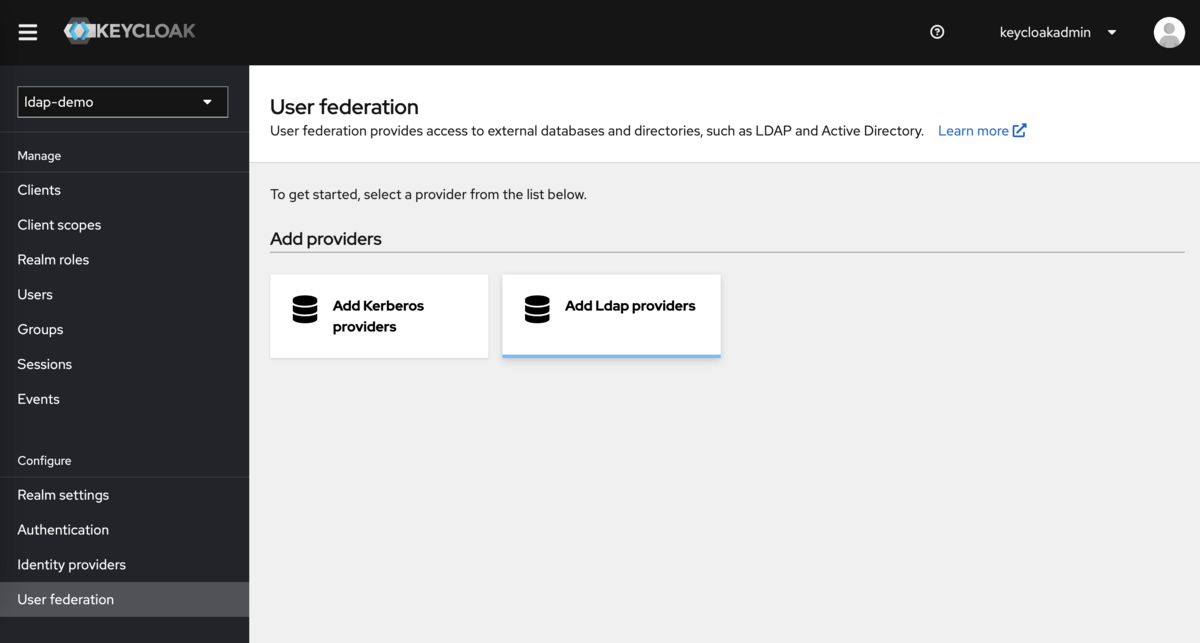
フェデレーション設定画面でLDAPサーバーの種類と接続情報を入力します。
General options > Vender (LDAPサーバーの種類) は Other を選択してください。
プルダウンにはADやTivoliといった選択肢が表示されますが、OpenLDAPの場合はOtherでよいです。
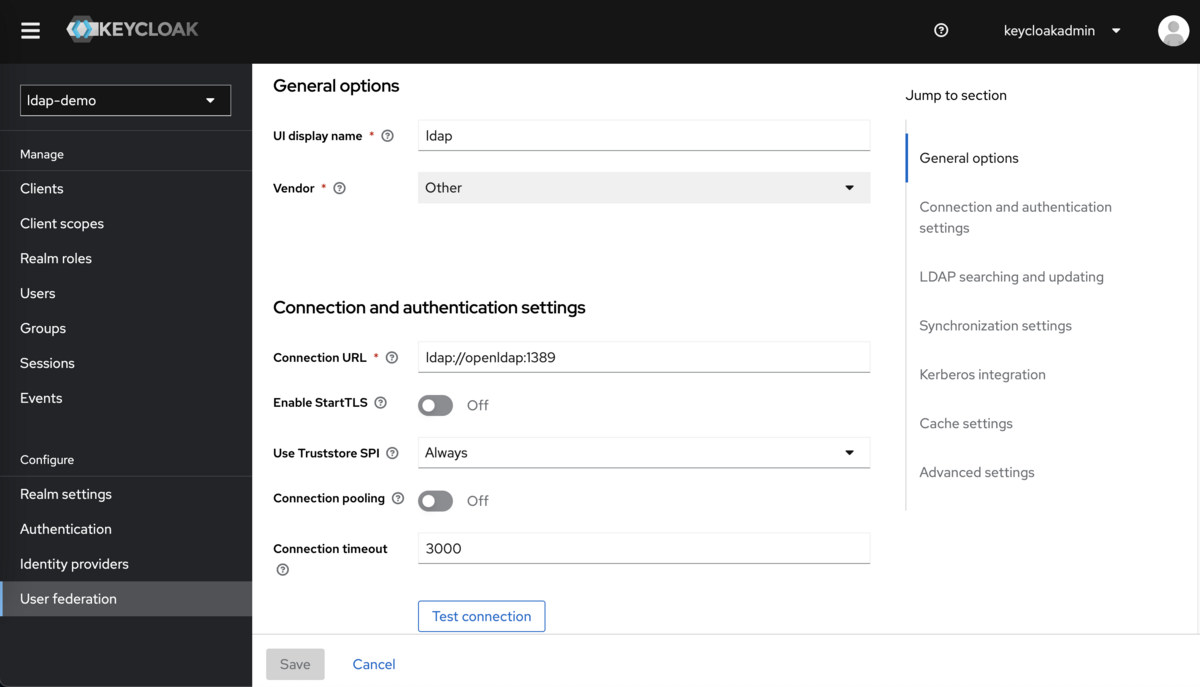
また、Connection and authentication settings (接続情報) は必須属性を埋めます。必須属性以外はデフォルト値のままでOKです。
接続情報の入力例を次の表と図で示します。今回はコンテナで構築しているので、LDAP URLはKeycloakコンテナから見たOpenLDAPのホスト名・ポート番号を指定してください。ホスト名に localhost を指定しても接続できないことに注意です。
| 設定名 | 設定値 |
|---|---|
| Connection URL | ldap://openldap:1389 |
| Bind type | simple |
| Bind DN | cn=admin,dc=example,dc=com |
| Bind credential | adminpassword |
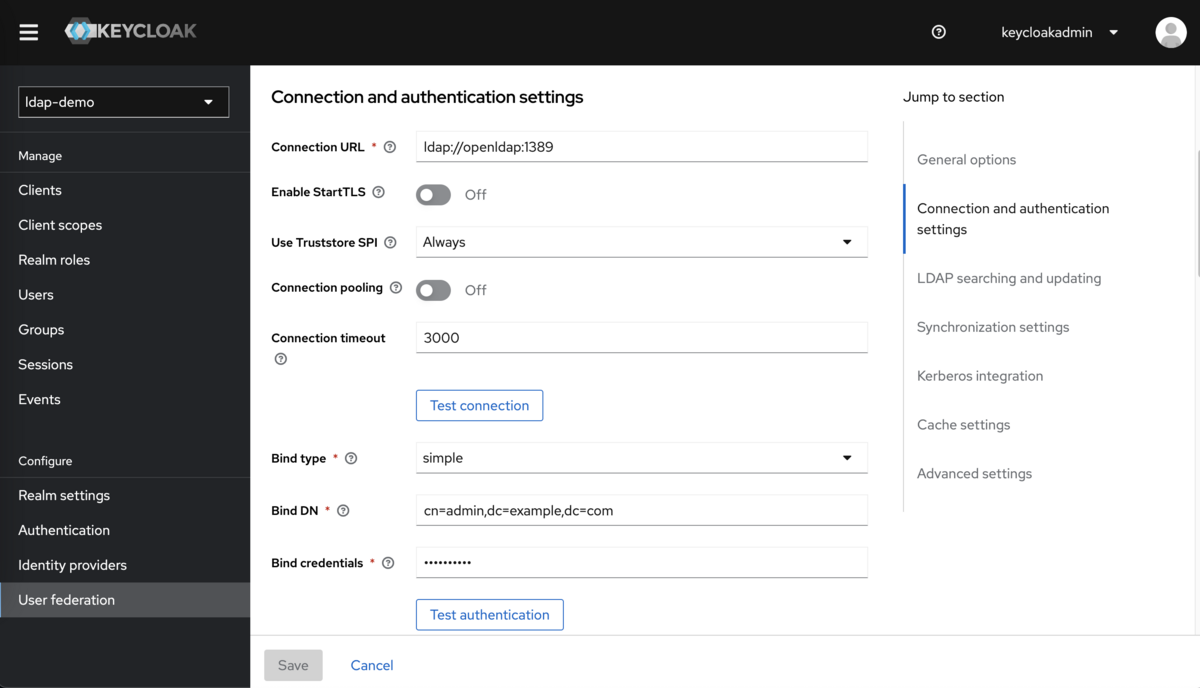
設定を埋めたら「Test connection」と「Test authentication」ボタンで疎通疎通確認します。 それぞれテストOKのポップアップが表示されたら疎通確認は完了です。
Keycloakが認証操作を実行するときにLDAPサーバーを検索する条件を設定します。
LDAP serching and updating の必須属性を埋めて保存します。入力例を次の表と図で示します。
今回はKeycloakからLDAPサーバーに属性変更操作を想定していないので、READ_ONLY を指定してください。
| 設定名 | 設定値 |
|---|---|
| Edit mode | READ_ONLY |
| Users DN | ou=users,dc=example,dc=com |
| Username LDAP attribute | uid |
| RDN LDAP attribute | uid |
| UUID LDAP attribute | uid |
| User object classes | inetOrgPerson, organizationalPerson |
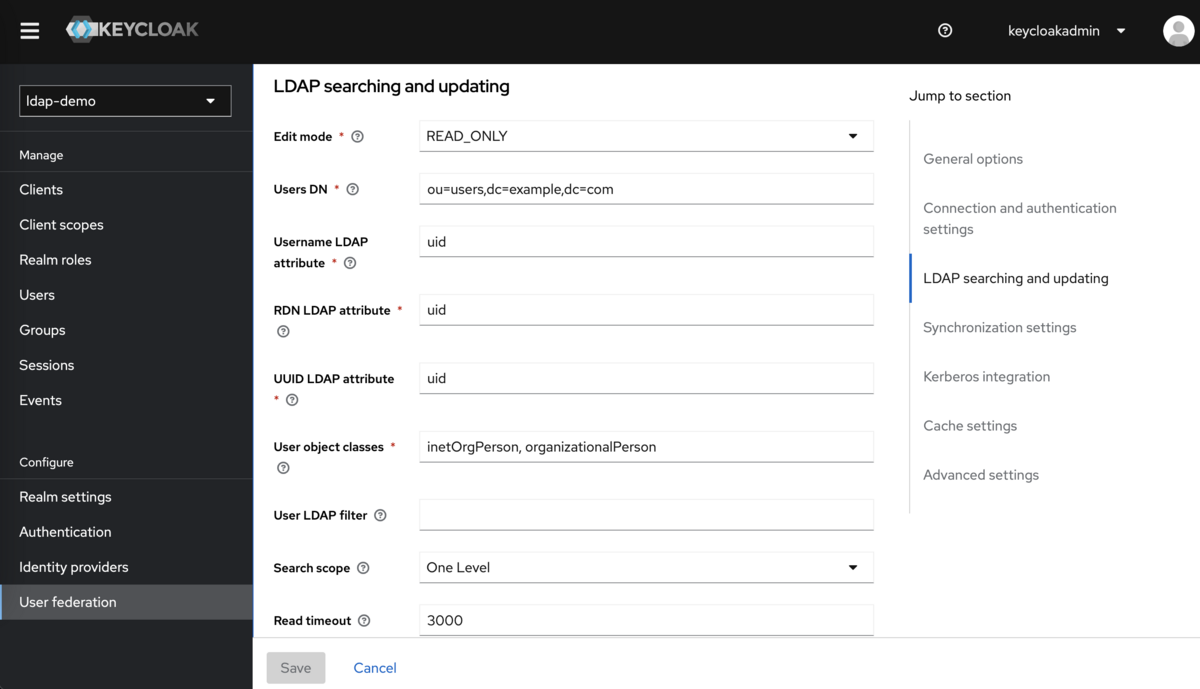
設定を全て埋めたら「Save」ボタンで設定を保存すれば完了です。
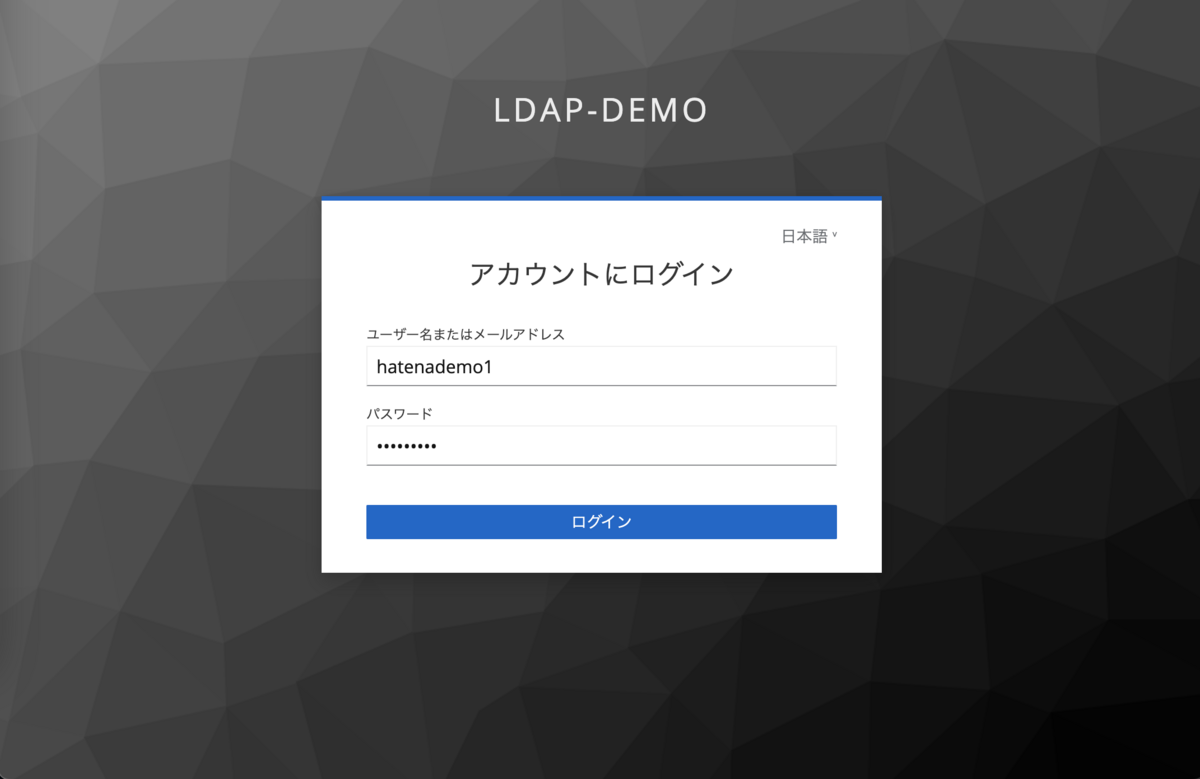
実際にLDAPユーザーで認証できるのか試します。 認証するOIDCクライアントアプリケーションとして、Keycloakが標準で用意しているアカウントコンソールを使用します。
アカウントコンソールのURL http://localhost:8080/realms/ldap-demo/account/ にアクセスしてアカウントコンソールを開きます。
Sign in ボタンを押下するとログインフォームが表示されるので、LDAPサーバーに登録済みのユーザーIDとパスワードを指定してログインできます。
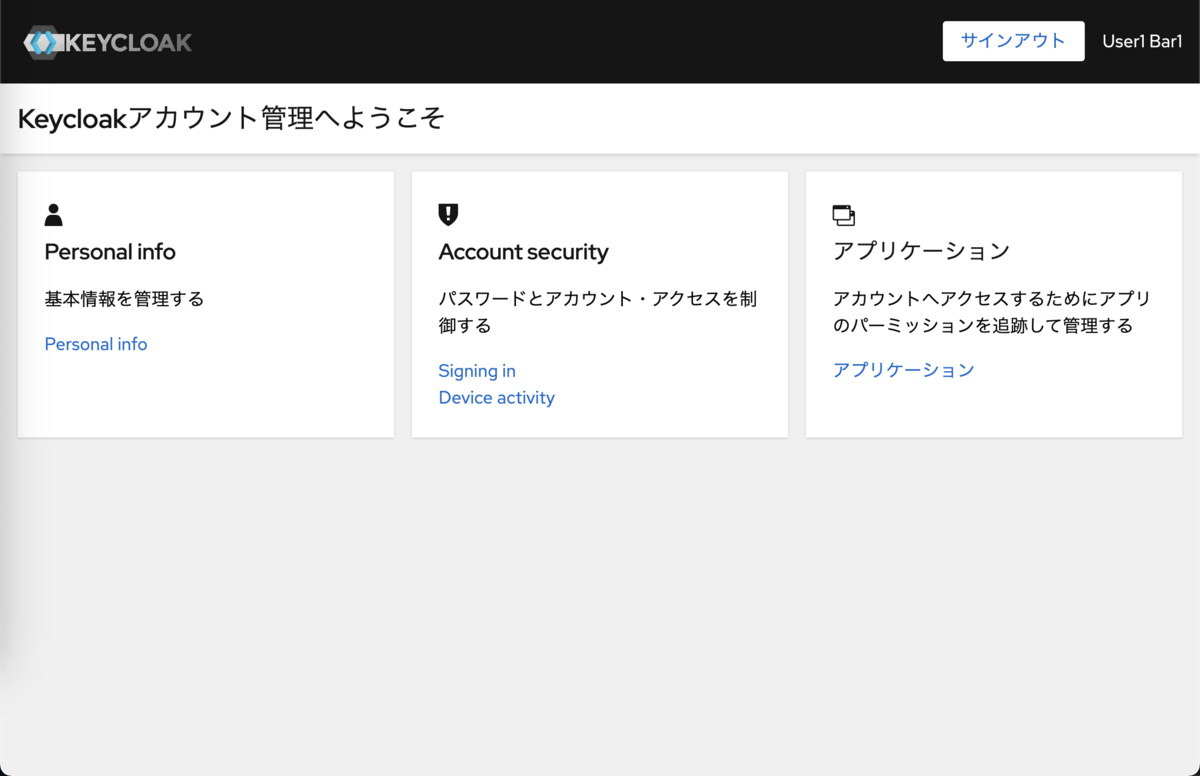
ログインに成功すると、アカウントコンソール右上にはLDAPサーバーに登録してあるユーザーの姓名が表示されています。
以上。